昨天看到北邮人 PT 出了一个新东方英语六级的资源,作为一个学习资源收集党,自然不能错过。不过一看大小是120 G 的,而我拿来挂 PT 的 INIZ 家的512 G 大硬盘VPS 就只剩20多个 G 了,本地的小水管网络拿来挂 PT 非常蛋疼,于是此时想起了才开了不到一个月的 DigtalOcean 家的 VPS 可以拿来一用。自带 IPV6 而且余额还挺足的,可以拿来暂时用一下。于是加了一个150 G 的 Volume 在原来的服务上,安装 Transmission 马上拉资源。
拉好后就要下到本地了,本地的网络在大约凌晨十二点后下行速度可以飙满100 M带宽。最终我是选择了用 HyperAPP 搭一个 WebDav 服务,这样可以有多线程下载而且还能保持原来的文件结构,资源的文件结构大概是这样的:
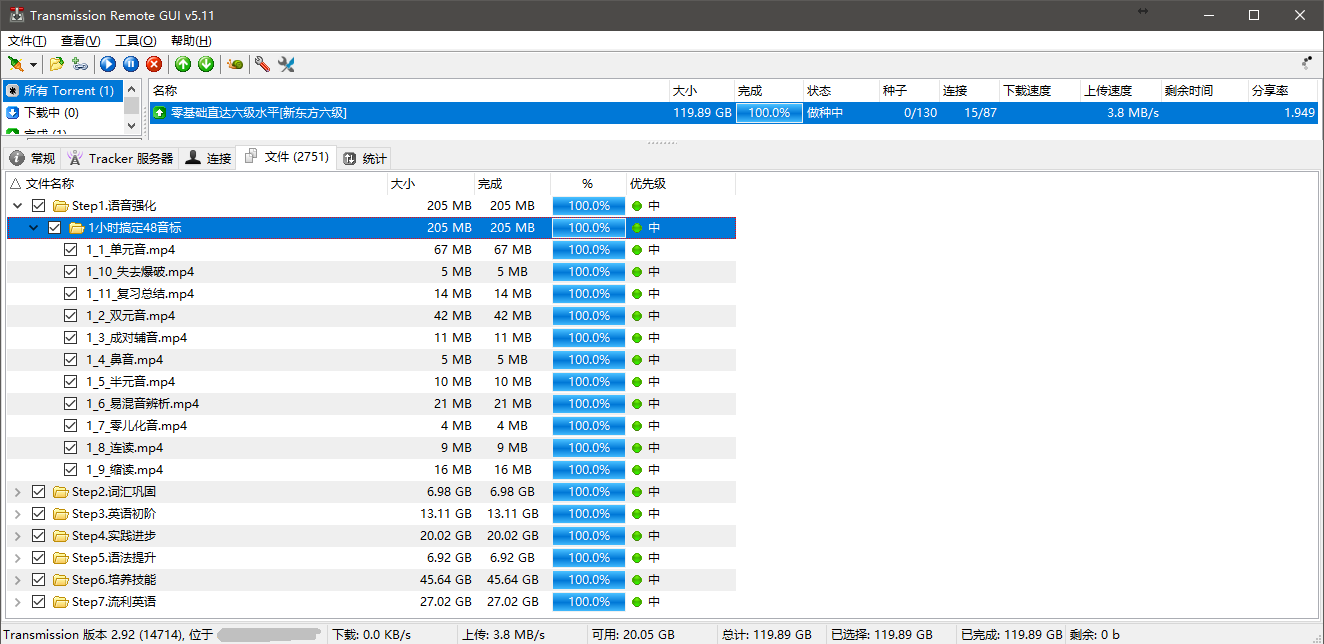
而我的 Volume 只是刚好装得下,没有空间再给我添加进压缩包了,所以用 nginx 开个 http 服务来下载不是很适用。而 sftp 没有多线程,突破不了本地 1M/s 的限速。
不过途中我还是钻研了下如果不考虑保持文件结构,直接下载的话要怎么做。我的思路是在服务器中遍历文件夹,把每个文件的绝对路径都放进一个 Text 文本里,然后在本地用 aria2 下载文本文件里的所有 urls。
首先是在服务器上写个 shell 脚本遍历文件夹里的所有文件。自从学了 Linux 操作后都没怎么写过 shell 脚本,对一些很常用的命令也不是很融会贯通,所以只能 Google 了。
function findAllFile() {
ls | while read var
do
if [[ -f $var ]]; then
echo $(pwd)/$var >> /usr/share/nginx/html/paths.txt
fi
if [[ -d $var ]]; then
cd "$(pwd)/$var"
findAllFile
cd ..
fi
done
}
findAllFile
其中有个坑就是有的文件名是有空格的,所以直接执行 ls 后存进变量的话因为空格的关系一个文件的名字会被识别为两个文件的名字。如果是上面那样写的话就不会出现这个情况了。
之后就拿到一个所有文件绝对路径的列表文本文件了,然后需要替换路径前面的部分,让其成为一个 url。由于对 shell 脚本不是太熟悉的关系,我就把文件拿到本地用 atom 替换了.. 不过其实好像用 sed 命令就能完成这个事情。
路径虽然变成 url 了,不过不能直接丢进 aria2,因为需要对里面的中文进行 url utf-8 encode,否则大概不能识别出来吧。然后我找了很多网上在线的转换工具,而我有大概3000个 url,这些工具有些不能只对中文编码,而有些又会把换行编码进去,于是只有查查资料用 python 写个。
import urllib, urllib.parse, string, linecache
path1 = 'H:/ariaDownloads/urls.txt'
path2 = 'H:/ariaDownloads/urls2.txt'
file = open(path2, 'a')
lines = linecache.getlines(path1)
for line in lines:
file.write(urllib.parse.quote(line, safe=string.printable))
用 python 还是挺简单地完成这件事。最后拿到了 url 的列表的文本,用 aria2 下载就可以了。
